

Data maintenance
Manage your application data

While extending your application and adding entities, attributes and associations you get to the point where you have to generate objects or associations to have a consistent data model and data. Here’s an example:
Assume you have the entities Company, User and Project and associations like in the datamodel below. All users within the company can access all projects of that same company.
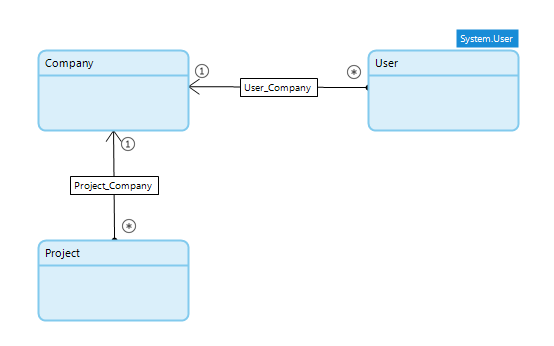
Assume you want to limit who has access to projects, then you have to change the model and administer that membership. The datamodel below is a simple solution to it.
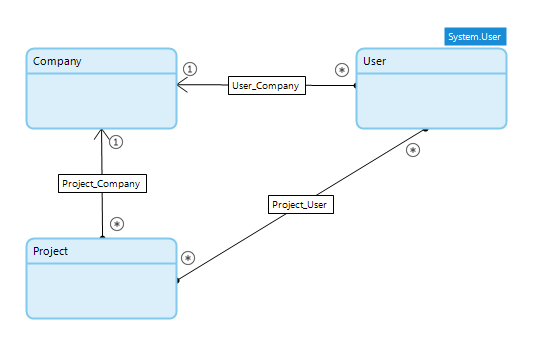
The new association between User and Project is added and you adjusted your pages and microflows to use this new association. For the existing databases on your development systems, on the test server, acceptance server and probably even the production server this association is never set. So when the application is deployed nobody can access any project anymore.
You have to generate the associations for existing data so the users can still access their projects and they are supposed to.
To do this you could create a microflow that is called via a button on a page which is accessible to admins only. And when you have other data migration microflows you can add them to the same page so you create a central place where you can run them. But how do you now if the data of the current database was migrated, so if the microflows ran? And what was the outcome? Who created the data migration microflow, why was it created and when?
To my opinion there’s a more elegant solution to migrate data than putting buttons on a page.
Criteria
To be able to manage data migration microflows and their execution (results) in a multi-admin environment I have some requirements:
- proper documentation as I am not the only developer/admin
- what does it do?
- who created it and when was that?
- does it have preconditions?
- when has it run?
- by who?
- what was the outcome?
- memory efficient and infinite loop safeguard
- prevent crashes due to memory overload
- prevent infinite loops while processing data in batches
- maintain these microflows over time
- mark them as retired or inactive and/or remove them hard from the model
- some sooner than others
- keep the logging for troubleshooting reasons later
- optionally run it automatically (scheduled event)
- perfect for housekeeping tasks
Mechanism
I have created a mechanism that consists of a number of elements that work together.
- standard data migration microflow templates to create your data migration scenario in
- maintain the metadata of such microflows
- access the microflows from a dashboard
- optionally let them run automatically as scheduled event
- retire obsolete microflows
All these elements are implemented in a module called DataMaintenance.
Microflow template
Each data migration microflow is created using a template, as found in folder MANAGEYOURSCRIPTSHERE/_Examples. Duplicate one of the two examples and use it to create the desired steps. The microflow uses color coded actions to guide you in what you can adjust and what should stay there because it takes care of logging and housekeeping.
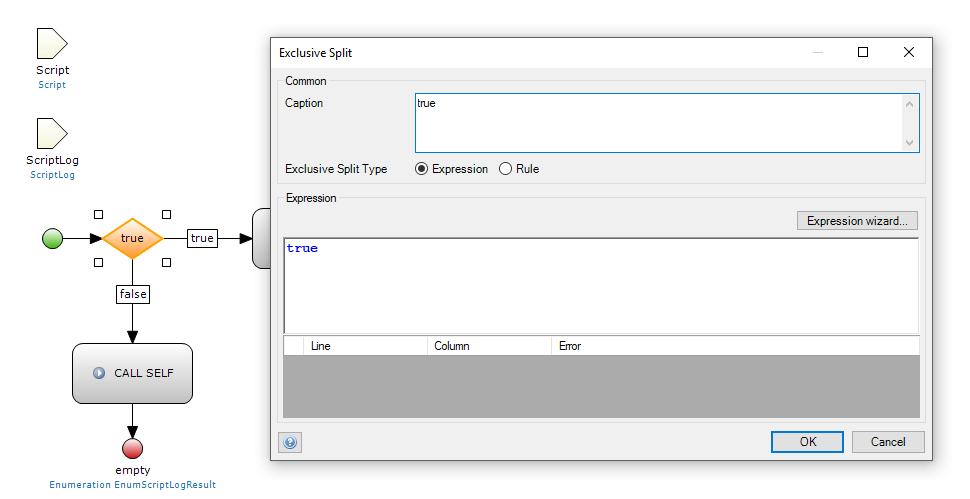
The data migration microflows are dynamically called via a Java action (see microflow MC_Script_RunScript_ExecuteScript) so the Mendix Modeler will mark these microflows as Unused document. To prevent this, every microflow calls itself while it never has the chance to. This is to keep the modeler quiet. The example below shows right after the start of the microflow an exclusive split with content true. The false flows contains a microflow action which calls the same microflow. So it will never get there and you fool the Mendix Modeler.
The dynamic calling of microflows, as mentioned before, requires that you use a specific naming convention:
- a prefix that depends on the type
- MC_Scheduled_ run automatically and can be run manually too
- MC_Manual_ run manually
- the rest is the name of the data migration script as defined in the metadata (see next paragraph)
As examples, the other folders in MANAGEYOURSCRIPTSHERE contain real data migration microflows. The folders are versions of the application.
- 001/MC_Scheduled_ScheduledEventInformation - automatic housekeeping of the System.ScheduledEventInformation table
- 002/MC_Manual_ConvertUserNamesToLowercase - the policy concerning usernames changed and new usernames are converted to lower case; so existing usernames have to be converted too
- 002/MC_Scheduled_FileDocument - automatically delete obsolete FileDocument objects where DeleteAfterDownload = TRUE
New microflows are administered in JSON files in filesystem folder resources/datamaintenance. Every JSON file contains one or more objects that describe a microflow and its attributes. The next paragraph describes this in detail.
Manage metadata
Using an after startup microflow you can import the metadata of your data migration microflows. Eventually you can call this manually, it saves very little startup time of your application. I recommend to run it automatically to ensure that new microflows are registered immediately and that changes to the metadata of existing microflows are made. Remember: the goal is to keep all copies of the application database up to date and to inform developers and admins about new and existing data migration microflows.
The goal is not to run these data migration microflows automatically at startup. You, the developer or admin, should be in control when to run certain data migration microflows. Potentially on large datasets a run can take hours to complete and you do not want to wait hours before the application is started.
Find microflow ASu_DataMaintenance and you will see how it works and why there are two JSON files defined in my example. The JSON file has to have a certain structure:
- unnamed array of AppVersion-Type combinations to group scripts of the same type and version
- AppVersion - string representing some kind of version; use what works best for you
- Type - enum value Scheduled or Manual to tell what type of microflows are in the next array
- Scripts - array of microflows
- Script - name of the script which is the same as the name of the microflow without the MC_prefix part
- AddedOn - date this script was added in yyyy-mm-dd format
- Developer - name of the developer who created this script
- Description - a proper description of what it does, eventually refer to user stories or other documentation
- Retired - boolean to tell if a script is active or retired; explained later
- DependsOn - comma separated list of scripts where this one depends on; the other scripts must have run at least once before this one is allowed to run
- DTAP - comma separated list of environments this script is allowed to run on; explained later
- BatchSize - the amount of objects to retrieve and process in each loop
- RunLimit - the maximum amount of objects to process; this prevents infinite loops
- DaysToKeep - for scheduled scripts the amount of days of data to keep; 0 for manual scripts
If you want to put all into one JSON file, that’s fine. You can split it per application version, per developer or any other criteria. The two provided JSON files are just examples. Simply do what works best for your application or team.
The mechanism to manage configuration data in external files has been described in blog post Manage configuration data before. It is a powerful development guideline to help developers manage application configuration data in every database.
After a while scripts become obsolete. The data has been migrated and the application works as expected. Retire the script(s) by changing the Retired attribute from false to true. At the next startup the script is marked as retired. That means that the past existence of the script and its runs (logging) are still available in the dashboard, but it cannot be executed anymore. At the same time the microflow can be deleted from the model.
It is a good practice to retire obsolete scripts at every new release of your application.
I have had scripts that stayed active to months. For example we were not able to solve a particular bug and we needed the script to fix data issues that were caused by the bug.
DTAP stands for Development-Test-Acceptance-Production and is a generic term in software development. Constant DTAPEnvironment has to get a value on each environment. The default value is Development which is easy for dynamic environments like developers have, but set it to proper values on your servers. In the JSON file you can use these values (strings) to specify on which environments a script is allowed to run. So for example, you could prevent a certain script to be run on production.
Dashboard
The dashboard, which is page Script_Dashboard, shows all scripts and their data. On the left hand side are the scripts, on the right hand side is the logging of the selected script.
Scheduled event
Scheduled event ScheduledScript runs the scripts automatically once per day (or any other interval you decide by adjusting the scheduled event). Have a look at microflow SE_ScheduledScript to understand which scripts it selects to run.
It was mentioned before that the microflow names of such scripts have a specific prefix. This helps the developer to see the purpose of the microflows while working with the Mendix Modeler. There’s no other reason for the prefix than this.
Conclusion
This might look like overkill if you never thought about this, but I can tell you that it is a nightmare to run an application on various servers and development systems that is hard to maintain. Building an application from scratch and deploy it to production once is easy, extend it with new features and maintain it for the next 5 years is something else. You have to be in control end to end and this blog post and related Mendix module is one step to help you.
The Mendix module can be downloaded here. Contact me to get access to a project where you can find the latest version of the module. At the time of writing it was created using Mendix 6.10.6 and it requires AppStore modules Community Commons (at least 6.2.2).
Twitter
Facebook
Reddit
LinkedIn
StumbleUpon
Pinterest
Email